fuzz命令行参数
计算需要的总字节数,布尔1bit,浮点数和整型用4/8字节,可变长度字符串用固定大小的数组
首先计算出新块需要的总字节数,取每个参数数据类型长度之和。示例中为50字节。
在输入文件前添加一个50字节的零块,该块内容将逐渐被fuzzer改变。
最后代码中加入代码片段,以便为每个块位置分配一个输入变量。

unsigned char arguments[50] = {0}; fread(arguments, 1, 50, inputFile); randomArg = (arguments[0] >> 7) & 1; loopArg = (arguments[0] >> 6) & 1; repeatArg = (arguments[0] >> 5) & 1; playAndExit = (arguments[0] >> 4) & 1; playAndStop = (arguments[0] >> 3) & 1; playAndPause = (arguments[0] >> 2) & 1; startPaused = (arguments[0] >> 1) & 1; playlistAutostart = (arguments[0] >> 0) & 1; memcpy(&grain-variance, arguments[1], 4); memcpy(&grain-period-min, arguments[5], 4); memcpy(&grain-period-max, arguments[9], 4); memcpy(scene-format, arguments[13], 50-13); //File content starts at inputFile[50]
分割比较
一个例子如下
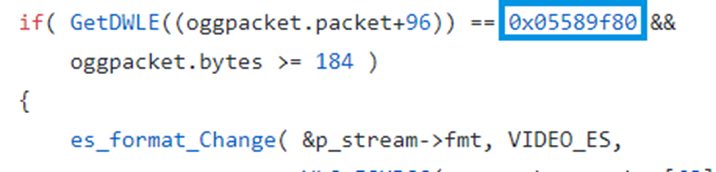
fuzzer不太可能碰巧得到这个确切的值 如果能将这个比较语句拆分成多个单字节比较语句,且每个比较语句都进行了检测,就会执行第一个嵌套if语句,从而发现新路径,进而向AFL发出信号,表明当前输入应该在进一步fuzz中再次使用。从而让fuzzer发现并通过该条件语句
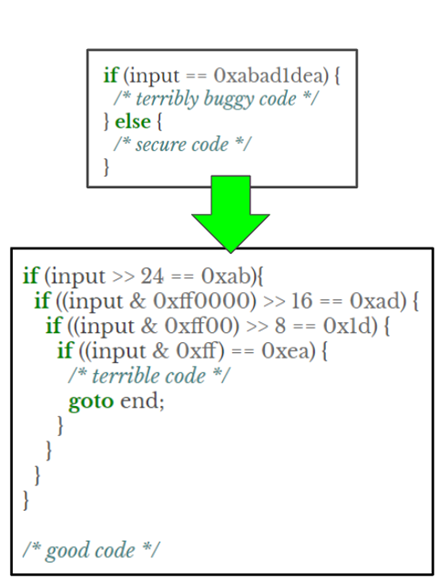
Laf-intel AFL plugin 插件就是干这个的
可以配置下面环境变量来处理
export AFL_LLVM_LAF_SPLIT_SWITCHES=1 export AFL_LLVM_LAF_TRANSFORM_COMPARES=1 export AFL_LLVM_LAF_SPLIT_COMPARES=1 export AFL_LLVM_LAF_SPLIT_FLOATS=1
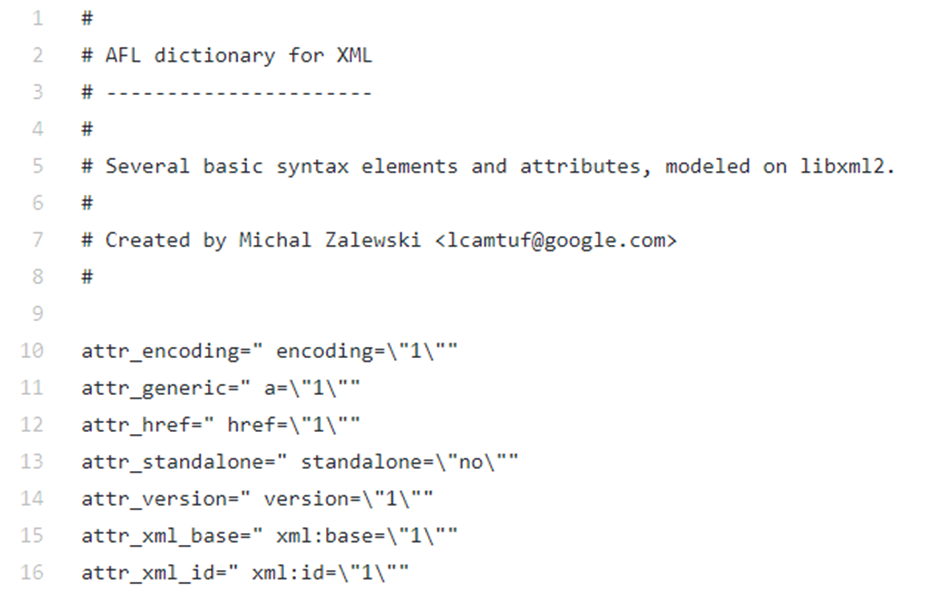
提供自定义字典
模块guid
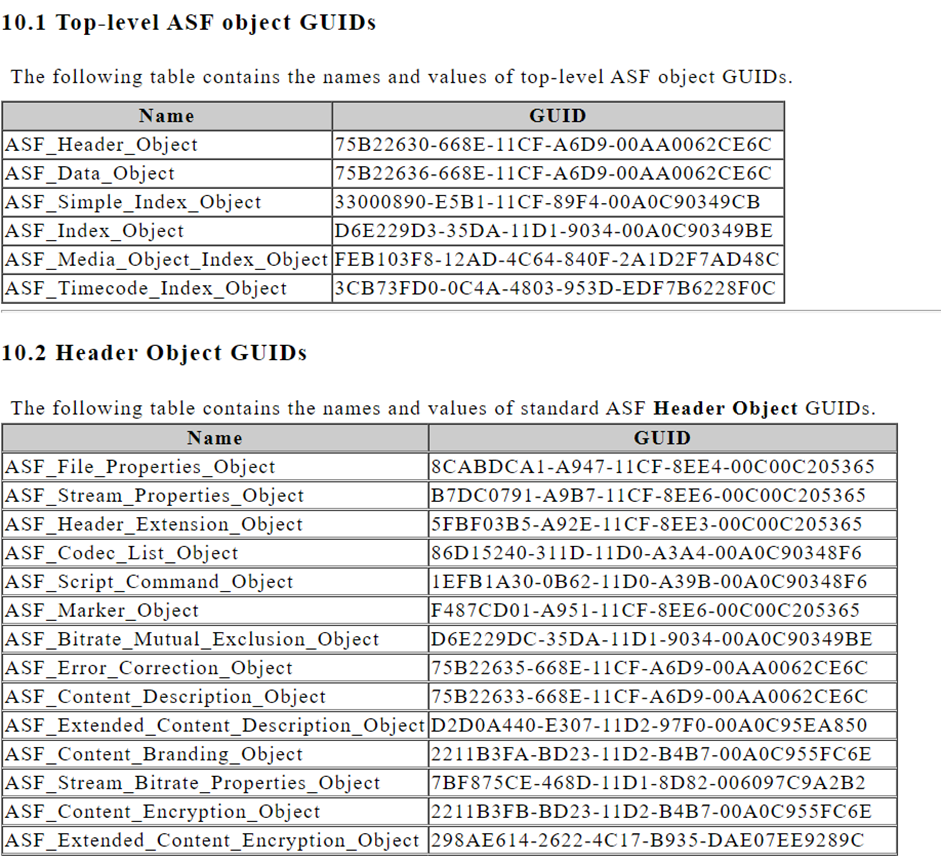
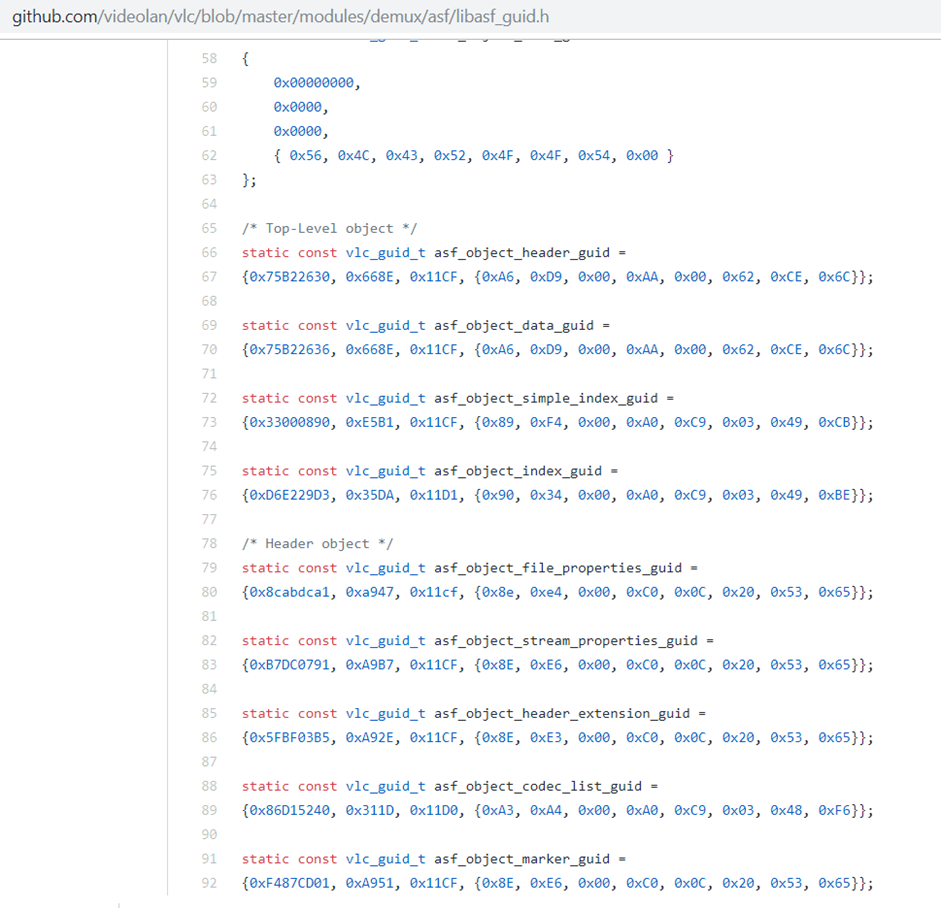
可以为fuzzer提供包含这些常数值的字典
Override:用n个字节替换特定位置,其中n是字典条目的长度。 Insert:将字典条目插入到当前文件位置,强制所有字符下移n个位置并增加文件大小。
可以用脚本或者codeql搜索 eg
import cpp from StringLiteral l, Call fc where l.getFile().getBaseName() = "ogg.c" and (fc.getTarget().getQualifiedName() = "memcmp" or fc.getTarget().getQualifiedName() = "strcmp") and fc.getAnArgument() = l select l.getValueText()
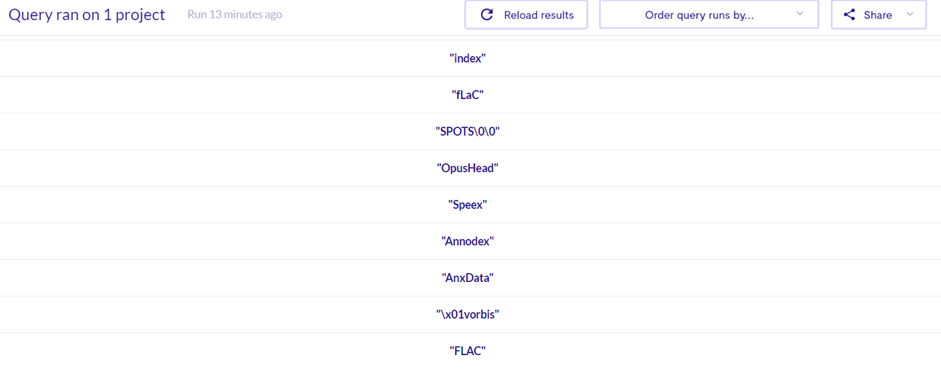
再看另一个例子,查找guid相关所有全局变量
import cpp from GlobalVariable gb where gb.getFile().getBaseName() = "libasf_guid.h" select gb
注意某些情况下需要反转字典条目的字节顺序
可以重构与目标相关语言的语法(xml sql)
 不过这种方法实践中似乎不太行
不过这种方法实践中似乎不太行
处理checksum
举例ogg媒体容器文件格式指定ogg页头如下

两种策略:
- 根据输入重新计算校验和
- 修改代码禁用校验和 并修复格式错误输入中的校验和字段 某些情况下 有的项目包含此目的的build flag,如disable-crc
还要对代码修改:
/* Compare */ if(memcmp(chksum,page+22,4)){ /* D’oh. Mismatch! Corrupt page (or miscapture and not a page at all) */ /* replace the computed checksum with the one actually read in */ memcpy(page+22,chksum,4)
注释掉memcmp语句即可避免crc检查
自定义覆盖率
如果不对代码覆盖率施加限制 fuzzer容易选择错误路径 造成效率降低
为解决此问题 afl++包含一个白名单特性,允许指定(在源文件级别)哪些文件应该使用或不使用插桩进行编译
该特性只在使用llvm时可用,要在编译时设置AFL_LLVM_WHITELIST变量,该环境变量指向一个包含所有应该检测的文件名的文件
还可以给每个白名单创建特定字典
reference
- https://securitylab.github.com/resources/fuzzing-challenges-solutions-1/
- https://securitylab.github.com/resources/fuzzing-software-2/